


当前位置:首页
> .html
导读:前言
在使用数据库的时候,最需要了解的知识点肯定就是索引,所以,针对索引希望能够整理出一些知识点,做个简单总结。
索引结构
B+树
B+树在之前的文章中已经做了简单介绍多种树结构分...
前言
在使用数据库的时候,最需要了解的知识点肯定就是索引,所以,针对索引希望能够整理出一些知识点,做个简单总结。
索引结构
B+树
B+树在之前的文章中已经做了简单介绍多种树结构分析
在InnoDB 索引结构最终选择了 B+ 树,主要是出于以下几点考虑:
- B+ 树的磁盘读写代价更低
B+树的非叶子结点不存储数据,只存储索引,所以,非叶子结点的存储结构更小。由于数据都存储在叶子结点,也减少了查询磁盘的次数。 - B+ 树查询效率更加稳定
所有数据都存储在叶子结点上,无论怎么查询所有关键字查询的路径长度是固定的。 - B+ 树对范围查询的支持更好
B+ 树所有数据都在叶子节点,非叶子节点都是索引,那么做范围查询的时候只需要扫描一遍叶子节点即可;而 B 树因为非叶子节点也保存数据,范围查询的时候要找到具体数据还需要进行一次中序遍历
MyISAM 和 InnoDB 索引组织的区别
- MyISAM 也是使用 B+ 树作为索引存储结构,他的叶子节点 data 域存放的是数据的物理地址,即索引结构和真正的数据结构其实是分开存储的。
- InnoDB 中采用主键索引的方式,所有的数据都保存在主键索索引中。这里就又可以联系到主键索引其实就是聚簇索引。
索引的分类
- 主键索引
上面讲了,主键索引为聚簇索引,是基于主键来创建的 B+ 树索引结构,如果没有指定主键,也找不到任何一列不重复的列可以作为主键的情况下,InnoDB 会新增一个隐藏列 RowId 作为主键继而创建聚簇索引。 - 二级索引
二级索引就是指除了主键索引外的索引。主键索引和所有的二级索引都是各自维护各自的 B+ 树结构,但是二级所以是非聚簇索引,叶子结点存储的不是数据,而是主键索引对应的主键值。所以,innodb中,使用二级索引需要查询两次B+树。
这里就牵出了索引失效的问题:
- 联合索引失效
联合索引对应的 B+ Tree 索引结构每个节点其实是按照三个字段的前后顺序排列的,即 a 字段检索在最前面,然后是b,然后是c。如果你的查询不是按照这个顺序来检索,是不会被这个索引识别的。我的理解在树结构上只保留a,叶子结点上以联合索引存储着具体的三个字段作为数据加上主键索引对应的主键值。这样其实就很好理解最左匹配原则了。当只有a为第一个条件,中间没有其他条件时,索引才生效。 - 在索引列上做操作(函数,自定义计算)
索引是对已有的数据进行归纳排序,你计算之后的数据是新的内容,索引并没有包含这些数据,无从查起。如果是运算,可以将运算方式变形,以适应索引规则。 - 查询条件包含 or,可能导致索引失效
or条件左右必须都加了索引在大多数情况下才可能会走,有些特殊场景不会走。这也是优化器优化后,发现没有走索引部分会引起全表扫描等,所以就直接不走索引了。 - like 通配符可能导致索引失效
只有以 “%” 开头的 like 查询才会失效。主要是因为左连接查询或者右连接查询查询关联的字段编码格式不一样,具体的试验可以后续尝试一下。
这里还能得出为啥创建过多的索引是崩溃性的:
- 磁盘空间占用。从上面可知,索引其实就是创建了一个B+树,如果是一张大表,每个索引会维护一张B+树,越多会越占用空间。
- 更新类操作。从之前的关于B+树的文章中,可以看到,一定程度上,更新类操作,是需要时间成本的,过多,过于复杂的索引,容易在更新时引起更多的消耗。
sql优化
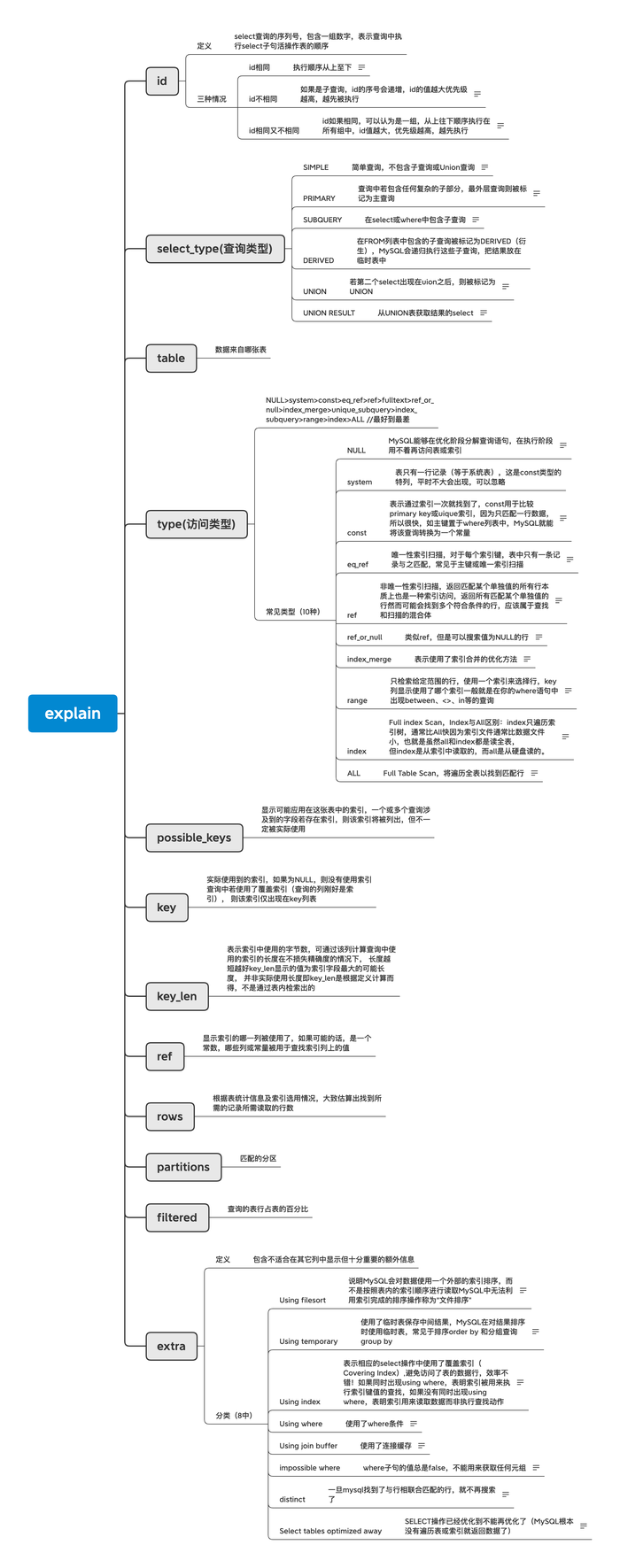
explain.png
具体案例待补充
相关文章

发表评论: