


4 聚合
对数据分组完后,可以使用一些函数对分组数据进行计算
最常用的就是 aggregate()(等于 agg()) 方法
In [67]: grouped = df.groupby("A")
In [68]: grouped.aggregate(np.sum)
Out[68]:
C D
A
bar 0.392940 1.732707
foo -1.796421 2.824590
In [69]: grouped = df.groupby(["A", "B"])
In [70]: grouped.aggregate(np.sum)
Out[70]:
C D
A B
bar one 0.254161 1.511763
three 0.215897 -0.990582
two -0.077118 1.211526
foo one -0.983776 1.614581
three -0.862495 0.024580
two 0.049851 1.185429
如你所见,聚合的结果将以组名作为分组轴的新索引。
在有多个分组键的情况下,结果默认是一个 MultiIndex,可以使用 as_index 参数来改变这一行为
In [71]: grouped = df.groupby(["A", "B"], as_index=False)
In [72]: grouped.aggregate(np.sum)
Out[72]:
A B C D
0 bar one 0.254161 1.511763
1 bar three 0.215897 -0.990582
2 bar two -0.077118 1.211526
3 foo one -0.983776 1.614581
4 foo three -0.862495 0.024580
5 foo two 0.049851 1.185429
In [73]: df.groupby("A", as_index=False).sum()
Out[73]:
A C D
0 bar 0.392940 1.732707
1 foo -1.796421 2.824590
当然,也可以使用 reset_index 达到相同的效果
In [74]: df.groupby(["A", "B"]).sum().reset_index()
Out[74]:
A B C D
0 bar one 0.254161 1.511763
1 bar three 0.215897 -0.990582
2 bar two -0.077118 1.211526
3 foo one -0.983776 1.614581
4 foo three -0.862495 0.024580
5 foo two 0.049851 1.185429
另一个简单的例子是,计算每个分组的大小。
In [75]: grouped.size()
Out[75]:
A B size
0 bar one 1
1 bar three 1
2 bar two 1
3 foo one 2
4 foo three 1
5 foo two 2
计算每个分组的基本统计信息
In [76]: grouped.describe()
Out[76]:
C ... D
count mean std min 25% 50% ... std min 25% 50% 75% max
0 1.0 0.254161 NaN 0.254161 0.254161 0.254161 ... NaN 1.511763 1.511763 1.511763 1.511763 1.511763
1 1.0 0.215897 NaN 0.215897 0.215897 0.215897 ... NaN -0.990582 -0.990582 -0.990582 -0.990582 -0.990582
2 1.0 -0.077118 NaN -0.077118 -0.077118 -0.077118 ... NaN 1.211526 1.211526 1.211526 1.211526 1.211526
3 2.0 -0.491888 0.117887 -0.575247 -0.533567 -0.491888 ... 0.761937 0.268520 0.537905 0.807291 1.076676 1.346061
4 1.0 -0.862495 NaN -0.862495 -0.862495 -0.862495 ... NaN 0.024580 0.024580 0.024580 0.024580 0.024580
5 2.0 0.024925 1.652692 -1.143704 -0.559389 0.024925 ... 1.462816 -0.441652 0.075531 0.592714 1.109898 1.627081
[6 rows x 16 columns]
可以使用 nunique 计算每个分组中唯一值的数量,与 value_counts 类似,但是它只计算唯一值
In [77]: ll = [['foo', 1], ['foo', 2], ['foo', 2], ['bar', 1], ['bar', 1]]
In [78]: df4 = pd.DataFrame(ll, columns=["A", "B"])
In [79]: df4
Out[79]:
A B
0 foo 1
1 foo 2
2 foo 2
3 bar 1
4 bar 1
In [80]: df4.groupby("A")["B"].nunique()
Out[80]:
A
bar 1
foo 2
Name: B, dtype: int64
聚合函数可以对数据进行降维,下面是一些常用的聚合函数:
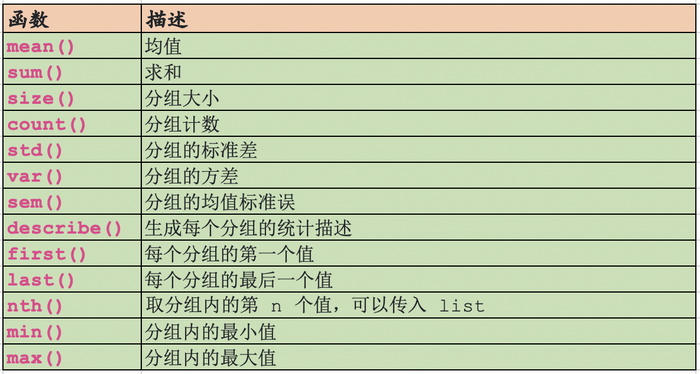
上面的函数都会忽略 NA 值。任何一个能够将 Series 转化为标量值的函数都可以作为聚合函数
4.1 同时应用多个函数
对于一个分组的 Series,可以传入一个函数列表或者字典,并输出一个 DataFrame
In [81]: grouped = df.groupby("A")
In [82]: grouped["C"].agg([np.sum, np.mean, np.std])
Out[82]:
sum mean std
A
bar 0.392940 0.130980 0.181231
foo -1.796421 -0.359284 0.912265
如果分组是 DataFrame,传入一个函数列表或字典,将会得到一个层次索引
In [83]: grouped.agg([np.sum, np.mean, np.std])
Out[83]:
C D
sum mean std sum mean std
A
bar 0.392940 0.130980 0.181231 1.732707 0.577569 1.366330
foo -1.796421 -0.359284 0.912265 2.824590 0.564918 0.884785
对于 Series 分组返回结果的列名默认是函数名,可以使用链式操作修改列名
In [84]: (
....: grouped["C"]
....: .agg([np.sum, np.mean, np.std])
....: .rename(columns={"sum": "foo", "mean": "bar", "std": "baz"})
....: )
....:
Out[84]:
foo bar baz
A
bar 0.392940 0.130980 0.181231
foo -1.796421 -0.359284 0.912265
对于 DataFrame 分组,操作类似
In [85]: (
....: grouped.agg([np.sum, np.mean, np.std]).rename(
....: columns={"sum": "foo", "mean": "bar", "std": "baz"}
....: )
....: )
....:
Out[85]:
C D
foo bar baz foo bar baz
A
bar 0.392940 0.130980 0.181231 1.732707 0.577569 1.366330
foo -1.796421 -0.359284 0.912265 2.824590 0.564918 0.884785
注意:
通常,输出的列名是唯一的,不能将同一个函数或两个同名函数应用于同一列
In [86]: grouped["C"].agg(["sum", "sum"])
Out[86]:
sum sum
A
bar 0.392940 0.392940
foo -1.796421 -1.796421
如果传入的是多个 lambda 函数,pandas 会自动为这些函数重命名为 <lambda_i>
In [87]: grouped["C"].agg([lambda x: x.max() - x.min(), lambda x: x.median() - x.mean()])
Out[87]:
<lambda_0> <lambda_1>
A
bar 0.331279 0.084917
foo 2.337259 -0.215962
4.2 命名聚合
GroupBy.agg() 中接受一种特殊的语法,用于控制输出的列名以及特定列的聚合操作,即命名聚合
- 关键字就是输出的列名
- 值是元组的形式,第一个元素是要选择的列,第二个元素为对该列执行的操作。
pandas提供了pandas.NamedAgg命名元组,其字段为['column', 'aggfunc'],是参数设置更加清晰
通常,聚合函数可以是可调用函数或字符串函数名
In [88]: animals = pd.DataFrame(
....: {
....: "kind": ["cat", "dog", "cat", "dog"],
....: "height": [9.1, 6.0, 9.5, 34.0],
....: "weight": [7.9, 7.5, 9.9, 198.0],
....: }
....: )
....:
In [89]: animals
Out[89]:
kind height weight
0 cat 9.1 7.9
1 dog 6.0 7.5
2 cat 9.5 9.9
3 dog 34.0 198.0
In [90]: animals.groupby("kind").agg(
....: min_height=pd.NamedAgg(column="height", aggfunc="min"),
....: max_height=pd.NamedAgg(column="height", aggfunc="max"),
....: average_weight=pd.NamedAgg(column="weight", aggfunc=np.mean),
....: )
....:
Out[90]:
min_height max_height average_weight
kind
cat 9.1 9.5 8.90
dog 6.0 34.0 102.75
pandas.NamedAgg 只是 namedtuple,与直接传入元组等价
In [91]: animals.groupby("kind").agg(
....: min_height=("height", "min"),
....: max_height=("height", "max"),
....: average_weight=("weight", np.mean),
....: )
....:
Out[91]:
min_height max_height average_weight
kind
cat 9.1 9.5 8.90
dog 6.0 34.0 102.75
如果你的列名不是有效的 Python 关键字,可以构建一个字典并解包
In [92]: animals.groupby("kind").agg(
....: **{
....: "total weight": pd.NamedAgg(column="weight", aggfunc=sum)
....: }
....: )
....:
Out[92]:
total weight
kind
cat 17.8
dog 205.5
注意:在 Python 3.5 或更早的版本,**kwargs 不会保留键的顺序
Series 也可以使用命名聚合,因为 Series 不需要选择列,所以值就只是函数或字符串函数名
In [93]: animals.groupby("kind").height.agg(
....: min_height="min",
....: max_height="max",
....: )
....:
Out[93]:
min_height max_height
kind
cat 9.1 9.5
dog 6.0 34.0
4.3 为列应用不同的函数
通过对 aggregate 传递一个字典,你可以为不同的列应用不同的函数
In [94]: grouped.agg({"C": np.sum, "D": lambda x: np.std(x, ddof=1)})
Out[94]:
C D
A
bar 0.392940 1.366330
foo -1.796421 0.884785
函数名也可以是字符串,但是使用前必须定义了该函数
In [95]: grouped.agg({"C": "sum", "D": "std"})
Out[95]:
C D
A
bar 0.392940 1.366330
foo -1.796421 0.884785
5 转换
transform 方法返回一个与分组对象索引相同(大小相同)的对象,该函数必须:
- 返回一个与分组大小相同或可广播到分组大小的结果。例如,一个标量,
grouped.transform(lambda x: x.iloc[-1]) - 在组上逐列操作
- 不能执行原地修改操作
例如,对数据进行分组标准化
In [98]: index = pd.date_range("10/1/1999", periods=1100)
In [99]: ts = pd.Series(np.random.normal(0.5, 2, 1100), index)
In [100]: ts = ts.rolling(window=100, min_periods=100).mean().dropna()
In [101]: ts.head()
Out[101]:
2000-01-08 0.779333
2000-01-09 0.778852
2000-01-10 0.786476
2000-01-11 0.782797
2000-01-12 0.798110
Freq: D, dtype: float64
In [102]: ts.tail()
Out[102]:
2002-09-30 0.660294
2002-10-01 0.631095
2002-10-02 0.673601
2002-10-03 0.709213
2002-10-04 0.719369
Freq: D, dtype: float64
In [103]: transformed = ts.groupby(lambda x: x.year).transform(
.....: lambda x: (x - x.mean()) / x.std()
.....: )
.....:
标准化之后,均值为 0,方差为 1
# 原始数据
In [104]: grouped = ts.groupby(lambda x: x.year)
In [105]: grouped.mean()
Out[105]:
2000 0.442441
2001 0.526246
2002 0.459365
dtype: float64
In [106]: grouped.std()
Out[106]:
2000 0.131752
2001 0.210945
2002 0.128753
dtype: float64
# 转换后的数据
In [107]: grouped_trans = transformed.groupby(lambda x: x.year)
In [108]: grouped_trans.mean()
Out[108]:
2000 1.167126e-15
2001 2.190637e-15
2002 1.088580e-15
dtype: float64
In [109]: grouped_trans.std()
Out[109]:
2000 1.0
2001 1.0
2002 1.0
dtype: float64
我们可以对比一下转换前后的数据分布
In [110]: compare = pd.DataFrame({"Original": ts, "Transformed": transformed})
In [111]: compare.plot()
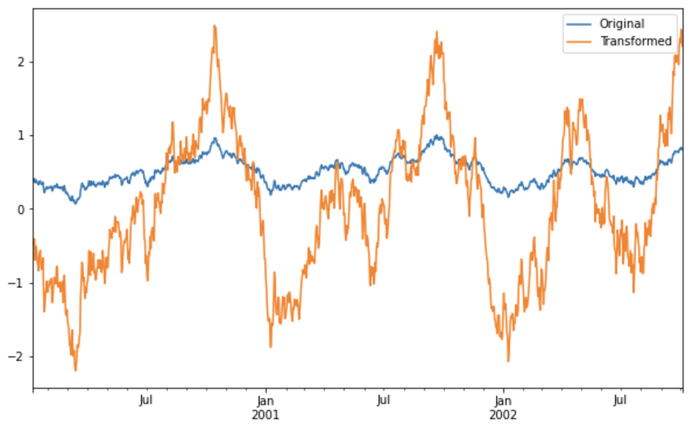
如果转换函数返回的是维度更低的结果,则将会把值进行广播,使其与输入数组大小一样
In [112]: ts.groupby(lambda x: x.year).transform(lambda x: x.max() - x.min())
Out[112]:
2000-01-08 0.623893
2000-01-09 0.623893
2000-01-10 0.623893
2000-01-11 0.623893
2000-01-12 0.623893
...
2002-09-30 0.558275
2002-10-01 0.558275
2002-10-02 0.558275
2002-10-03 0.558275
2002-10-04 0.558275
Freq: D, Length: 1001, dtype: float64
也可以使用内置函数,生成一样的结果
In [113]: max = ts.groupby(lambda x: x.year).transform("max")
In [114]: min = ts.groupby(lambda x: x.year).transform("min")
In [115]: max - min
Out[115]:
2000-01-08 0.623893
2000-01-09 0.623893
2000-01-10 0.623893
2000-01-11 0.623893
2000-01-12 0.623893
...
2002-09-30 0.558275
2002-10-01 0.558275
2002-10-02 0.558275
2002-10-03 0.558275
2002-10-04 0.558275
Freq: D, Length: 1001, dtype: float64
另一种常用的数据转换是,使用组内均值对缺失值进行填补。
例如,有如下数据
>>> data_df = pd.DataFrame(np.random.normal(0.5, 2, size=(1000, 3)), columns=list('ABC'))
>>> data_df.loc[np.random.randint(0, 1000, 100), 'C'] = np.NaN
>>> data_df
A B C
0 -1.807563 0.742651 0.582211
1 -0.004608 -0.252184 -0.599312
2 -0.682971 2.702668 1.314856
3 1.074685 0.203833 -2.223385
4 1.296123 2.436668 2.844688
.. ... ... ...
995 -2.413651 3.576030 0.209219
996 -0.501723 -0.510921 0.247469
997 -0.944480 -0.244293 -1.765085
998 -0.121340 -0.633210 -2.152916
999 -0.699248 -3.046279 1.562404
[1000 rows x 3 columns]
补缺失值
In [117]: countries = np.array(["US", "UK", "GR", "JP"])
In [118]: key = countries[np.random.randint(0, 4, 1000)]
In [119]: grouped = data_df.groupby(key)
# Non-NA count in each group
In [120]: grouped.count()
Out[120]:
A B C
GR 248 248 236
JP 243 243 213
UK 269 269 234
US 240 240 220
In [121]: transformed = grouped.transform(lambda x: x.fillna(x.mean()))
我们可以进行验证,转换前后均值并没有发生变化,但是,转换后已经不包含缺失值了
In [122]: grouped_trans = transformed.groupby(key)
In [123]: grouped.mean() # 原始数据的分组均值
Out[123]:
A B C
GR 0.744238 0.682563 0.671818
JP 0.637438 0.406635 0.476871
UK 0.343826 0.649000 0.489756
US 0.430899 0.276287 0.624809
In [124]: grouped_trans.mean() # 转换后均值不变
Out[124]:
A B C
GR 0.744238 0.682563 0.671818
JP 0.637438 0.406635 0.476871
UK 0.343826 0.649000 0.489756
US 0.430899 0.276287 0.624809
In [125]: grouped.count() # 转换前,行数不一致
Out[125]:
A B C
GR 248 248 236
JP 243 243 213
UK 269 269 234
US 240 240 220
In [126]: grouped_trans.count() # 转换后,行数一致
Out[126]:
A B C
GR 248 248 248
JP 243 243 243
UK 269 269 269
US 240 240 240
In [127]: grouped_trans.size() # count 与 size 的结果一致,不存在缺失值
Out[127]:
GR 248
JP 243
UK 269
US 240
dtype: int64
相关文章

发表评论: